-
머신러닝 7과정 실습ML&DL&AI/ML 2023. 8. 4. 14:13728x90
1. 문제정의
- 500명의 키, 몸무게 데이터를 통해서 비만도 계산하기
- 머신러닝의 과정을 이해하기
2. 데이터 수집
- 라이브러리 불러오기
- import numpy as np = 수치계산용 라이브러리
- import pandas as pd = 행과 열을 가지는 표와 같은 형태의 데이터를 다루는 라이브러리
- import matplotlib.pyplot as plt = 시각화 라이브러리
import numpy as np import pandas as pd import matplotlib.pyplot as plt- 데이터 읽어오기(data 라는 변수에 넣기)
- 단 label > 인덱스로 만들어주기
data = pd.read_csv('data/bmi_500.csv', index_col= 'Label') data
- 데이터 크기 확인하기
- .size = 전체 크기
- .shape = 행과 열
data.shape # 행과 열(500, 3)- 데이터의 전체 정보 확인하기
- data.info()
- 전체행, 컬럼 정보, 결측치
- 결측치 여부 확인 : Non-Null Count > 데이터가 있는 수
data.info()<class 'pandas.core.frame.DataFrame'> Index: 500 entries, Obesity to Extreme Obesity Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Gender 500 non-null object 1 Height 500 non-null int64 2 Weight 500 non-null int64 dtypes: int64(2), object(1) memory usage: 15.6+ KB3. 데이터 전처리
- 전처리가 필요하지 않다.
4. EDA 탐색적 데이터 분석
- 시각화, 기술통계량 확인
- 시각화를 통해 데이터 분포 현황 파악
- 기술통계량 확인
- count : 데이터의 개수
- mean : 평균
- std : 표준편차 / 데이터의 흩어진 정도를 파악
- 4분위수
- 최대값 , 최소값
data.describe()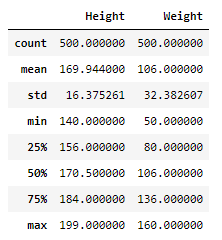
- Label(정답데이터)의 클래스 확인
- 정답 데이터 : 범주형 데이터 > 분류형 모델 사용
- data.index.uniqe() 중복되지 않은 유일한 값들만 출력
Index(['Obesity', 'Normal', 'Overweight', 'Extreme Obesity', 'Weak','Extremely Weak'], dtype='object', name='Label')- 데이터 분포 시각화
- 산점도 (Sccater)
- 먼저 하나의 클래스 'Extreme Obesity' 데이터 시각화
- Extreme Obesity 데이터만 추출
- plt.scatter(x축,y축)
- plt.scatter(EO)
EO = data.loc['Extreme Obesity'] # 고도비만의 키 데이터만 추출 EO['Height'] # 고도비만의 몸무게 데이터만 추출 EO['Weight'] EO = data.loc['Extreme Obesity'] plt.scatter(EO['Height'],EO['Weight'],color = 'purple', label = 'Extreme Obesity' ) plt.legend()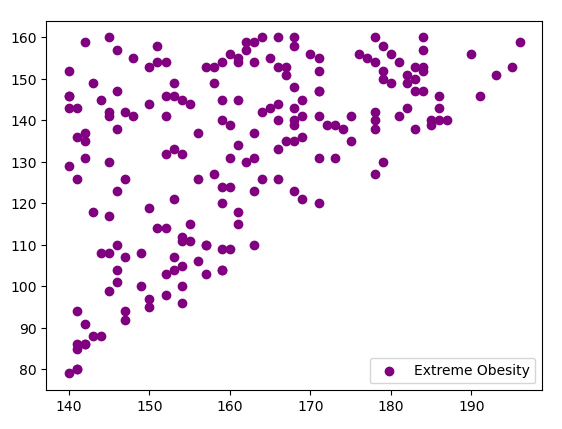
- 6개의 클래스들의 분포를 하나의 차트에 그려보기
# 고도비만'Extreme Obesity' EO = data.loc['Extreme Obesity'] plt.scatter(EO['Height'],EO['Weight'], color = 'purple', label = 'Extreme Obesity') # Obesity': 비만 O = data.loc['Obesity'] plt.scatter(O['Height'],O['Weight'], color = 'blue', label = 'Obesity') #'Overweight': 과체중 OW = data.loc['Overweight'] plt.scatter(OW['Height'],OW['Weight'], color = 'green', label = 'Overweight') # Normal': 정상 N = data.loc['Normal'] plt.scatter(N['Height'],N['Weight'], color = 'yellow', label = 'Normal') #'Weak': 저체중 W = data.loc['Weak'] plt.scatter(W['Height'],W['Weight'], color = 'orange', label = 'Weak') #'Extremely Weak': 심한저체중 EW = data.loc['Extremely Weak'] plt.scatter(EW['Height'],EW['Weight'], color = 'red', label = 'Extremely Weak') plt.legend() plt.show()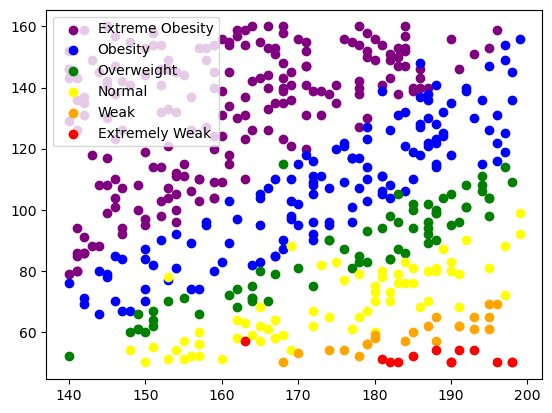
- 모델링
- 데이터 분리 (문제, 정답)
- 문제 : 키, 몸무게
- 정답 : Label (비만도)
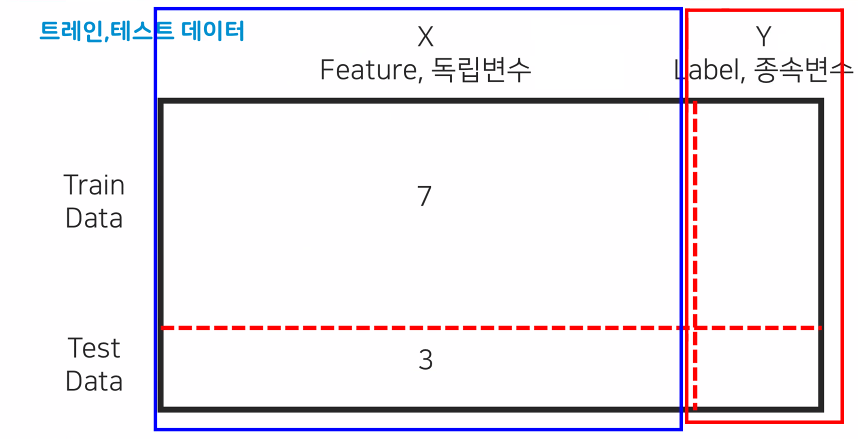
# 문제 데이터 x = data[['Height','Weight']] # 정답 데이터 y = data.index- 훈련용 문제, 답과 테스트용 문제, 답의 비율은 7:3
- 우리가 가지고 있는 데이터는 한정적이기 때문에
x_train = x.iloc[0:350] y_train = y[0:350] x_test = x.iloc[350:] y_test = y[350:]5. 모델 객체 생성 및 하이퍼파라미터 조절
- 머신러닝 패키지 sklearn(사이킷런)
- 정확도 측정도구
from sklearn.neighbors import KNeighborsClassifier # knn 분류모델 from sklearn.metrics import accuracy_score # 정확도 측정도구- 모델 객체 생성
knn_model = KNeighborsClassifier()6. 학습
- knn_model.fit(학습용문제, 학습용정답)
knn_model.fit(x_train, y_train)KNeighborsClassifier()- 예측
- knn_model.predict(테스트용 문제)
pre = knn_model.predict(x_test)7.평가
- 정확도 평가
- accuracy_score(예측, y_test)
accuracy_score(pre, y_test)0.9066666666666666728x90'ML&DL&AI > ML' 카테고리의 다른 글
KNN 실습 - 붓꽃(iris) 품종 구분하기 (0) 2023.08.09 ML KNN(최근접 이웃 알고리즘)란 (0) 2023.08.08 머신러닝의 과정 (0) 2023.08.04 머신러닝의 종류 (0) 2023.08.04 인공지능의 바라보는 시선 (0) 2023.08.04