ML&DL&AI/ML
KNN 실습 - 붓꽃(iris) 품종 구분하기
Hoon0211
2023. 8. 9. 13:56
728x90
1. 문제 정의
- 붓꽃 3가지 품종을 구분하는 모델 만들기
2. 데이터 수집
- sklearn에서 제공하는 데이터 셋 이용
from sklearn.datasets import load_iris
iris_data = load_iris()
- 데이터 확인하기
iris_data.keys()dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])- data : 특성 데이터 (입력 데이터) 문제 데이터
- target : 타깃 데이터(출력 데이터) 답지 데이터
- DESCR : 데이터셋에 대한 설명
- feature_names : 특성의 이름
- target_names : 타깃 클래스의 이름

- 데이터 분류 및 설명
- 문제 데이터(X 데이터)
iris_data['data']
# iris_data.data 방식도 가능하다.
- sepal 꽃받침
- petal 꽃잎
iris_data['feature_names']
- 정답 데이터(Y 데이터)
iris_data['target']
- feature_names : 특성의 이름
iris_data['target_names']
- DESCR : 데이터셋에 대한 설명
print(iris_data['DESCR'])
- file name
iris_data['filename']
3. 데이터 전처리
iris_data['data'].shape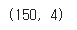
- 데이터 dataframe으로 변경
import pandas as pd
X = pd.DataFrame(iris_data['data'], columns = iris_data['feature_names'])X.info()
- 데이터 요약
X.describe()
4. EDA 탐색적 데이터 분석
- 산점도 그리기
- c - target(0,1,2) 색상을 부여
- marker - 점의 모양
- alpha - 투명도
import matplotlib.pyplot as plt
pd.plotting.scatter_matrix(X,
figsize = (15,15),
c = iris_data['target'],
# c = iris_data.target,
marker = 'o',
alpha = 0.7
)
plt.show()
5. 모델 선택 및 하이퍼 파라미터 튜닝
- 문제 데이터
# X = pd.DataFrame(iris_data['data'], columns = iris_data['feature_names'])
X
- 정답 데이터(Label)
# iris_data['target']
y = iris_data.target
y
- train / test 나누기
- 총 150ea
- 7:3 비율로 나누기
X_train = X.iloc[0:105]
X_test = X.iloc[105:]
y_train = y[0:105]
y_test = y[105:]
- 데이터 크기 확인
X_train.shape, X_test.shape
# ((105, 4), (45, 4))
y_train.shape, y_test.shape
# ((105,), (45,))
- 이러면 문제가 발생한다.
- 데이터가 한쪽으로 편중되는 현상이 발생
- 사이킷런에서 제공하는 함수 train_test_split를 이용
from sklearn.utils.fixes import sklearn
# 데이터를 랜덤하게 섞어서(train)과 평가(test)로 분리해주는 함수
# X_train, y_train, X_test, y_test
# X_train, X_test, y_train, y_test
# X_train, X_val, y_train, y_val, X_test
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=6)
6. 학습
- 모델 선택
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit (X_train, y_train)
7. 예측 및 평가
- 입력 데이터에 대한 예측값을 반환
pre = knn_model.predict(X_test)
pre # X_test에 대한 예측 값
y_test # 실제값
- score 확인하기 방법 1
- knn_model.score(input_data, true_data)
knn_model.score(X_test,y_test) # 검증(evaluate)0.9777777777777777
- score 확인하기 방법 2
- accuracy_score(실제값, 예측값)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,pre)0.9777777777777777
8. 하이퍼 파라미터 튜닝
- K값 범위 지정
- train, test 정확도 비교
- 반복문을 사용해서 튜닝 후 결과를 한번에 확인하기
# 결과를 지정할 변수 지정
train_acc = []
test_acc = []
# 이웃의 수만 조절 1~71 까지 바꾸기
n_setting = range(1,71)
# for i in ragne():
for n in n_setting:
# 모델 생성
knn_model = KNeighborsClassifier(n_neighbors=n) # 1~70까지
# 모델 학습
knn_model.fit(X_train,y_train)
# train 데이터 score 확인
train_score = knn_model.score(X_train, y_train)
# test 데이터 score 확인
test_score = knn_model.score(X_test, y_test)
# train, test score 저장 append()
train_acc.append(train_score)
test_acc.append(test_score)
- 정확도 검사 결과 확인하기
train_acc
test_acc
- 하이퍼 파라미터의 결과를 그래프로 확인하기
import matplotlib.pyplot as plt
plt.figure(figsize=(10,4))
plt.plot(n_setting, train_acc, label='Train_Acc', marker='o')
plt.plot(n_setting, test_acc, label='Train_Acc', marker='o')
plt.grid() # 격자 형태로 그래프 그리기
plt.xticks(range(1,71,2)) # X축 그래프에 표현되는 범위
plt.xlabel('n_neighbors') # X축 이름
plt.ylabel('Accuracy') # Y축 이름
plt.legend() # label 표시하기
plt.show()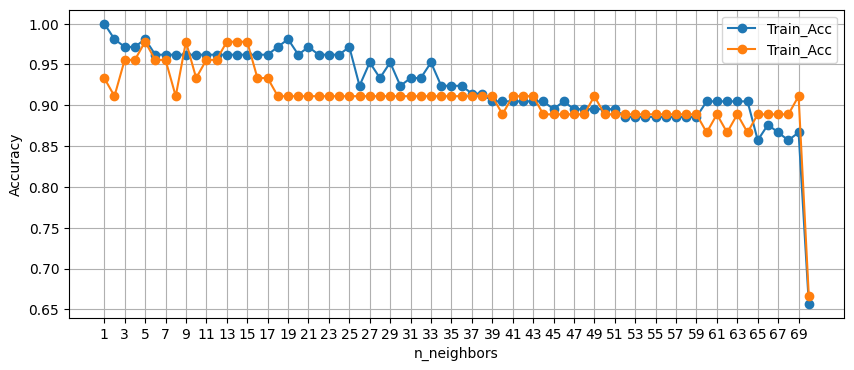
728x90