ML&DL&AI/ML
ML KNN(최근접 이웃 알고리즘)란
Hoon0211
2023. 8. 8. 13:42
728x90
1. K-Nearest Neighbors(최근접 이웃 알고리즘)
- 유유상종의 개념과 유사하다
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측한다.
- K 값에 따라 가까운 이웃의 수가 결정된다.
- 분류와 회귀에 모두 사용 가능하다.
2. KNN 개념 정리
- K 값이 작을수록 모델의 복잡도가 상대적으로 증가(noise 값에 민감)
- 반대로 K 값이 커질수록 모델의 복잡도가 낮아짐
- 100개의 데이터를 학습하고 K를 100개로 설정하여 예측하면 빈도가 가장 많은 클래스 레이블로 분류
> 과소 적합(안 좋은 분류 모델)


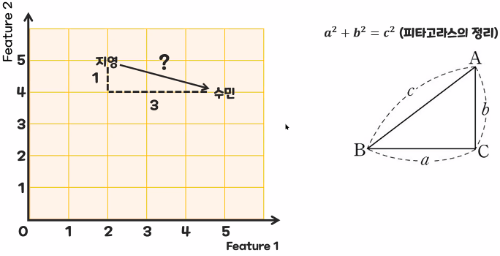
3. KNN의 거리 공식

4. KNN 장단점 및 키워드
- n_neighbors : 이웃의 수
- metrics : 유클리디안 거리 방식
- 새로운 테스트 데이터 세트가 들어오면,
훈련데이터 세트와의 거리를 계산해서 훈련 데이터 세트가 크면(특성, 샘플의 수) 예측이 느려짐 - 수백 개의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터 세트에는 잘 동작 안 함
- 거리를 측정하기 때문에 같은 scale을 같도록 정규화가 필요
728x90