-
앙상블(Ensemble) 모델ML&DL&AI/ML 2023. 8. 16. 09:20728x90
1. 앙상블(Ensemble)
- 여러 개의 머신 러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
- 앙상블 모델 방식
- voting
- bagging
- boosting
* boosting방식을 많이 사용한다.
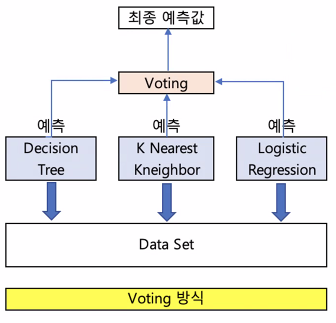
2. Voting 방식
- 서로 다른 모델을 결합하여 투표를 통해 최종 예측 결과를 결정하는 방식
- 하드 보팅 vs 소프트 보팅
- 하드 보팅
- 예측한 결과값들 중 다수의 분류기가 결정한 예측한 값을 최종 보통 결과값으로 선정하는 방식
- 다수결의 윈칙이라고 생각
- 소프트 보팅
- 분류기들의 레이블 값 결정 확률을 모두다 더한 뒤,
평균 해서 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정
- 분류기들의 레이블 값 결정 확률을 모두다 더한 뒤,

3. Bagging 방식
- 같은 알고리즘으로 여러개의 모델을 만들어서 투표를 통해 최종 예측, 결과를 결정하는 방식
- ex) 랜덤 포레스트

4. Boosting
- 성능이 낮은 여러 개의 모델을 이용
- 처음 모델이 예측을 하면 그 예측 결과에 따라 잘못 분류된 데이터에 가중치가 부여
- 부여된 가중치가 다음 모델에 영향
- 잘못 분류된 데이터에 집중하여 개선된 분류 규칙을 만드는 단계를 반복하여 성능을 높은 모델을 만듬
- ex) AdaBoost, GradientBoost, XGBoost
5. Bagging vs Boosting
비교 Bagging Boosting 특징 병렬 앙상블 모델
(각 모델이 서로 독립적)연속 앙상블 모델
(이전 모델의 오차를 고려)대표 알고리즘 Random Forest AdaBoost, Gradient Boosting,
XGBoost데이터 선택 무작위 선택 무작위 선택
(오류 데이터에 가중치 적용)
6. 랜덤 포레스트(RandomForest)
- 여러 개의 결정 트리 분류 모델이 전체 데이터에서 각자의 데이터를 샘플링해서 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 소프트 보팅을 통해 예측을 수행
- 서로 다른 데이터를 가지고 다른 방향으로 학습된 과대 적합 된 모델을 많이 만들고 평균을 내어 일반화 시키는 모델
- 다양한 트리를 만드는 방법
- 트리를 만들 때 사용하는 데이터를 무작위로 선택
- 노드 구성 시 기준이 되는 특성을 무작위로 선택
- 분류와 회귀가 모두 가능
- 랜덤 포레스트 사용 방법
# 라이브러리 불러오기 from sklearn.ensemble import RandomForestClassifier #랜덤 포레스트 분류 모델 생성 함수 호출, 분류 모델 객체 생성 rf_clf = RandomForestClassifier(매개변수, hyperparameter)- 주요 매개 변수
- 결정 트리 분류 모델의 개수
- n_estimators
- 사용할 결정 트리 분류 모델 개수
- 선택할 데이터의 시드
- random_state
RandomForestClassifier(n_estimators, random_state)728x90'ML&DL&AI > ML' 카테고리의 다른 글
ML 모델 성능 평가(K-fold cross-validation, GridSearchCV) (0) 2023.08.21 ML AdaBoost(Adaptive Boosting) (0) 2023.08.16 ML Decision Tree (0) 2023.08.14 KNN 실습 - 붓꽃(iris) 품종 구분하기 (0) 2023.08.09 ML KNN(최근접 이웃 알고리즘)란 (0) 2023.08.08